Dans le cadre d’une POC (proof of concept), d’un projet personnel ou d’une étude statistique, vous pouvez être amené à devoir scraper un site web. Le scraping est l’automatisation, via un script, de la récupération de certaines données mises à disposition par un site. Dans cet article nous considérons que vous avez des notions de base en web scraping.
La législation étant floue et la jurisprudence hésitante en termes de scraping, nous ne pouvons que vous déconseiller de le pratiquer à des fins commerciales mais nous allons néanmoins vous montrer comment mettre en place un système de scraping avec rotation d’IP grâce à
Python,
Scrapy et
Scrapoxy.
Cas du Client Side Rendering : Exploiter l’API
Pour les sites fonctionnant en
client side rendering, vous pouvez essayer d’exploiter directement l’API qui renvoie les données brutes (souvent au format JSON ou XML) à votre navigateur qui, lui, se chargera de les injecter dans le HTML. Pour cela, vous pouvez regarder (dans l'outil de développement de votre navigateur dans la section “network”) les requêtes XHR qui partent lorsque vous rafraîchissez la page web à scraper. Une fois que vous avez trouvé la ou les requêtes qui chargent les données que vous souhaitez récupérer, il ne reste plus qu’à essayer de forger cette même requête au sein d’un script Python (par exemple en utilisant la bibliothèque request). Ainsi, pas besoin de passer par du scraping à proprement parler (pas de headless webdriver, parser, xpath, etc).
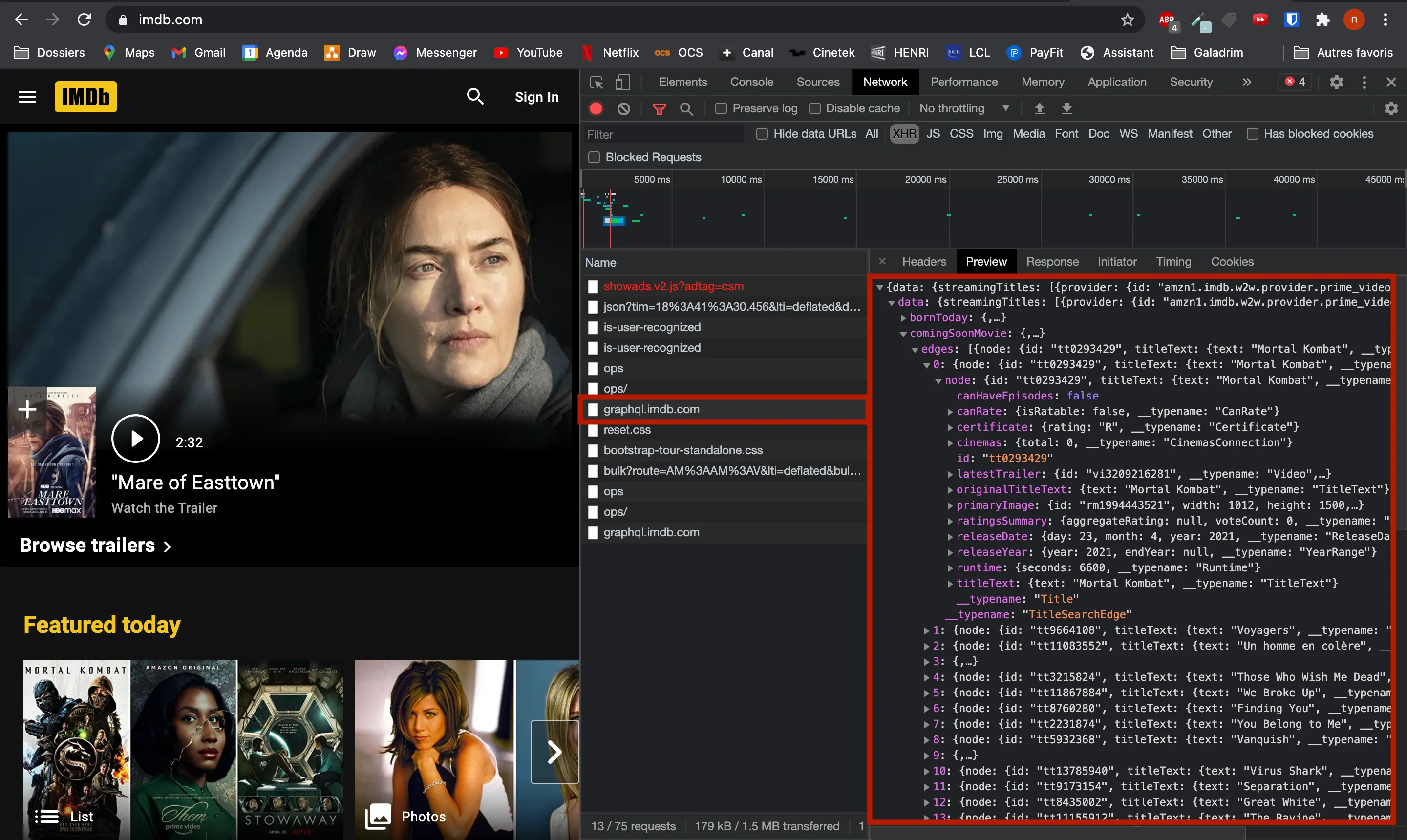
Ici par exemple sur le site de IMDB on pourrait essayer d'exploiter leur API GraphQL.
Ce n’est que dans le cas où l’API se révèle trop difficile à exploiter que je sors l’artillerie lourde pour scraper des données affichées grâce à Javascript : Selenium.
Cas du Server Side Rendering
Pour les sites en server side rendering (et fonctionnant sans appel API), vous n’avez pas d’autre choix que de parser le HTML de la page via une bibliothèque de parsing comme
Beautiful Soup et d’extraire les données via leur
xpath.
Si votre projet de scraping est conséquent, je vous conseille de vous tourner vers
Scrapy, un framework Python de crawling et de scraping assez complet qui permet notamment de tester vos xpath via un terminal ou d'intégrer divers plugins comme
Splash, ce qui permet d’activer le Javascript sur les pages web.
Notre problème : le bannissement d’IP
Parfois les sites utilisent des méthodes de prévention envers les scrapers. L’une des méthodes les plus redoutables qui m'a longtemps donné du fil à retordre est le bannissement d’IP. Le site scrapé analyse en direct les requêtes qu’il reçoit. S’il constate qu’une IP fait trop de requêtes pour être un utilisateur humain lambda, il peut bannir cette IP (pour une durée plus ou moins longue). Ainsi, à la prochaine requête, votre script lèvera une erreur due à une réponse 429 du serveur.
Première solution - mettre des sleep
Pour contrer cette méthode la première solution simple à laquelle on pourrait penser serait de mettre des “sleep” entre nos différentes requêtes pour ralentir l'exécution de notre script et ne pas se faire repérer par le site scrapé. Mais supposons qu’on ait 30 000 pages à scraper avec 30 secondes de sleep entre deux requêtes, il faudrait que le script tourne plus de 10 jours pour arriver au bout de la liste de pages. Cette solution fonctionnera certainement avec une valeur de “sleep” assez grande mais deviendra donc interminable à l'exécution.
Seconde solution - rotation d’IP avec Scrapoxy
Une autre solution beaucoup plus robuste et rapide à l'exécution (car ne contient pas de sleep) est d’utiliser le service open source
Scrapoxy. Scrapoxy permet de faire du scraping en redirigeant les requêtes par un ensemble de proxys. Ces proxys sont des instances de serveurs hébergés par le service EC2 d’AWS.
Récapitulatif de la solution étudiée dans cet article
Une spider (instance de scraping de Scrapy) se promène de lien en lien (“crawl” un ensemble de pages)
Les requêtes de Scrapy vers le serveur du site ciblé ne sont pas effectuées par votre machine directement mais sont redirigées vers des containers EC2 grâce au service Scrapoxy.
Dès qu’un container voit son IP se faire bloquer, Scrapoxy relance une nouvelle armée de containers pour remplacer les anciens devenus inutilisables.
Pré-requis :
Pour suivre ce tuto, il vous faut avoir Python et l’utilitaire pip installés sur votre machine.
Création et configuration du compte AWS
Création du compte
Si vous n’en avez pas déjà, créez-vous un compte
AWS afin de pouvoir accéder aux différents services disponibles sur la console AWS. En particulier EC2, le service qui fournit des serveurs à la demande et qui sera utilisé par Scrapoxy pour créer les proxys qui redirigeront nos requêtes. Pour vous créer un compte ça se passe
ici.
Remarque : Vous allez devoir mettre vos informations de carte bleue, alors essayez d'être vigilant quant à l'utilisation du service EC2 qui possède un bon Free Tier (750h d’utilisation par mois en cumulé sur toutes vos instances) mais qui n’est pas gratuit indéfiniment. Ainsi si vous avez 10 instances EC2 qui tournent en parallèle, vous commencerez à être facturé au bout de 750 / 10 = 75h.
Création de credentials IAM
Pour que Scrapoxy ait le droit de gérer pour vous vos instances EC2, il faut que vous génériez un couple de clé
access key et
secret access key. Pour cela, rendez-vous dans la console AWS, dans vos
identifiants de sécurité (
ici)
Dépliez la section Access Key et cliquez sur ajouter une clé. Gardez de côté la valeur de l’access key id. Cliquez ensuite sur “Show secret access key” et notez bien la valeur qu’il vous donne ou télécharger le key file.
Attention : Vous ne pourrez plus l’afficher par la suite.
Création d’un Security Group
Vous devez aussi créer un groupe de sécurité. Pour cela allez dans la console AWS sur le service EC2 et plus précisément sur les groupes de sécurité (sur cet URL, en remplaçant le paramètre region par la région que vous utilisez : https://console.aws.amazon.com/ec2/v2/home?region=us-east-1#SecurityGroups)
Remarque : Nous vous conseillons de vous mettre dans la région eu-west-1
Cliquez sur le bouton “Créer un groupe de sécurité”, puis :
Choix d’un AMI
Plus tard, lors de la configuration de Scrapoxy, vous allez avoir besoin d’un “AMI”.
Si vous êtes dans la région eu-west-1, vous pouvez choisir l’un de ces trois AMI en fonction de quel type d’instance vous voulez créer pour votre script :
t1.micro ⇒ ami-c74d0db4
t2.micro ⇒ ami-485fbba5
t2.nano ⇒ ami-06220275
Gardez dans un coin le nom l’AMI choisi pour plus tard !
Conseil : Essayez avec le premier (ami-c74d0db4), qui génère des instances t1.micro (les plus petites possible). En effet on va demander à ces serveur de faire de simples requêtes HTTP ; pas besoin de lancer des machines de guerre.
Si par contre, vous n’êtes pas dans la région eu-west-1, vous devrez suivre
ce tutoriel trouvé dans la doc de Scrapoxy pour copier l’AMI ami-c74d0db4 vers une AMI qui vous appartient situé dans votre région.
Installation et configuration de Scrapoxy
Installation de Scrapoxy
Pour installer
Scrapoxy veuillez entrer les commandes suivantes dans un terminal :
sudo apt-get install build-essential
sudo npm install -g scrapoxyConfiguration de Scrapoxy
Pour utiliser Scrapoxy et le lier à votre compte AWS, vous devez générer et remplir un fichier de configuration. Commencez par entrer la commande suivante :
scrapoxy init conf.json
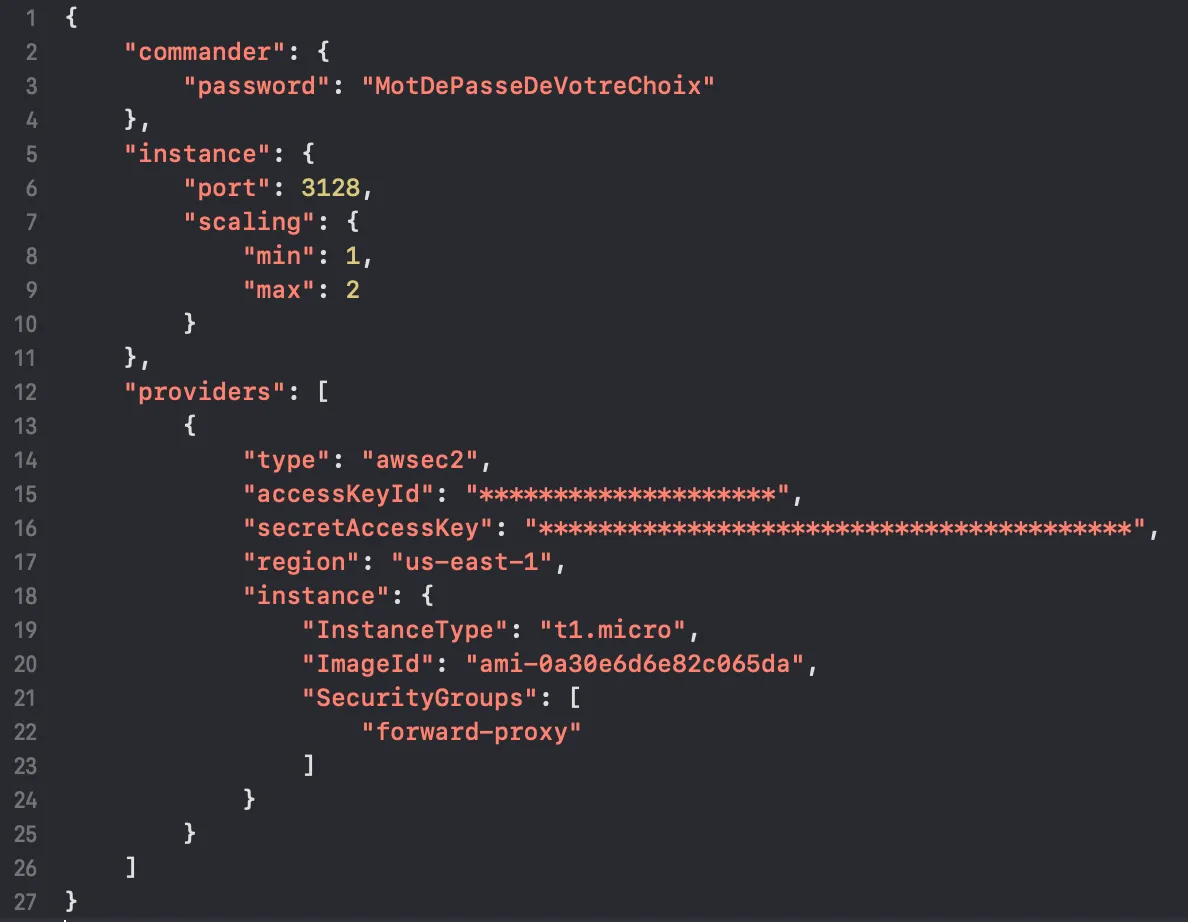
Ensuite dans le fichier conf.json qui vient d’être généré :
changez le password dans la section commander (mettez ce que vous voulez, ce mot de passe servira pour accéder à l’interface graphique de Scrapoxy)
dans la section provider, ne conservez que l’objet avec comme type : “awsec2”
puis remplacez les accessKeyId et secretAccessKey de cet objet par les credentials récupérés juste avant sur AWS
remplacez également la valeur de l’AMI (champ ImageId) par la bonne valeur
Vous n’avez pas besoin de toucher aux paramètres liés au nombre d’instances EC2, vous pourrez régler ça directement via l’interface graphique après avoir lancé Scrapoxy.
Lancement de Scrapoxy en local
Pour lancer une instance de Scrapoxy sur votre machine, entrez dans un nouveau terminal la commande :scrapoxy start conf.json -d
Ce terminal doit rester ouvert durant toute la durée d’exécution du script que nous allons vous présenter juste après. L’instance de Scrapoxy aura le rôle de dispatcher les requêtes entre les différents containers EC2, d’analyser les réponses, et de reboot les containers quand une requête échoue.
Installation et utilisation de Scrapy
Installer Scrapy
Pour installer
Scrapy avec l’utilitaire pip, entrez la commande :
pip install scrapy scrapoxyCréer un nouveau projet Scrapy
Pour créer un nouveau projet (une nouvelle “spider”), entrez dans un terminal la commande :
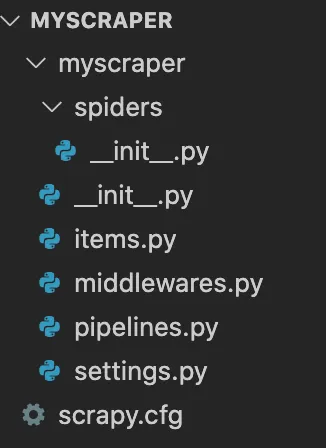
scrapy startproject myscraper
Cette commande créera un dossier myscraper qui aura cette arborescence :
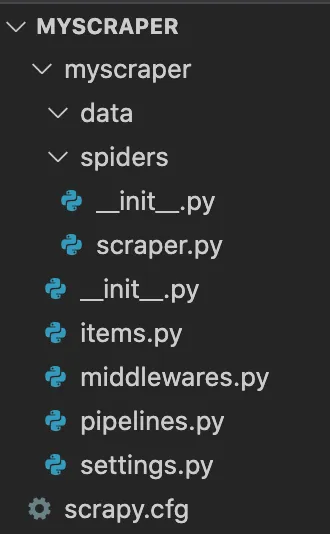
Créez un dossier data dans le sous-dossier myscraper et un fichier scraper.py dans le sous-dossier spider pour arriver à cette arborescence :
Intégrer Scrapoxy à la Spider
Pour intégrer Scrapoxy à votre spider et que les requêtes soient faites par vos instances EC2 plutôt que par votre machine, dans myscraper/myscraper/settings.py, ajouter les lignes :CONCURRENT_REQUESTS_PER_DOMAIN = 1
RETRY_TIMES = 0
PROXY = 'http://127.0.0.1:8888/?noconnect'
API_SCRAPOXY = 'http://127.0.0.1:8889/api'
API_SCRAPOXY_PASSWORD = 'CHANGE_THIS_PASSWORD'
BLACKLIST_HTTP_STATUS_CODES = [ 429 ]
DOWNLOADER_MIDDLEWARES = {
'scrapoxy.downloadmiddlewares.proxy.ProxyMiddleware': 100,
'scrapoxy.downloadmiddlewares.wait.WaitMiddleware': 101,
'scrapoxy.downloadmiddlewares.scale.ScaleMiddleware': 102,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
'scrapoxy.downloadmiddlewares.blacklist.BlacklistDownloaderMiddleware': 950
}
Si le site que vous scrapez renvoie un status code différent de 429 pour indiquer que votre IP a été bloquée, vous pouvez le spécifier en ajoutant la valeur du status code renvoyé par le site dans la variable BLACKLIST_HTTP_STATUS_CODES.
Écriture de la Spider
Passons maintenant au coeur du script de scraping : la spider.
Une spider Scrapy est composée de plusieurs parties :
Voici un exemple de code d’une spider avec dans la méthode parse() des exemple de façon de récupérer les données sur une page parsée. Pour en savoir plus, consultez directement la documentation de Scrapy ou renseignez vous sur la notion de xpath (
ici).
Vous pouvez copier ce code dans le fichier scraper.py que vous avez créé un peu plus tôt. Ensuite il vous suffit de reprendre le code pour l’adapter à votre site cible.import scrapy
import csv
class Scraper(scrapy.Spider):
name = u'scraper'
custom_settings = {
'FEED_FORMAT': "csv",
'FEED_URI': './data.csv',
'FEED_EXPORT_ENCODING': 'utf-8'
}
allowed_domains = ['www.site-url.com']
start_urls = [f"www.site-url.com/page?id={id}" for id in range(100)]
def start_requests(self):
total = len(self.start_urls)
for i in range(total):
print(f"############################## {i}/{total} #############################")
url = self.start_urls[i]
yield scrapy.Request(url, self.parse, meta={"url": url})
def parse(self, response):
data_0 = response.xpath("//div[@id='main-content']").text
data_1 = response.xpath("//div[@id='main-content']/div/div/div/div[2]/div/div/div/div/img/@src").extract_first()
data_2_raw = response.xpath("//category-div")
data_2 = ""
for data_2_item in data_2_raw:
title = data_2_item.xpath("./@title").extract_first()
data_2 += "{}:".format(title)
links = data_2_item.xpath("./div/div/div[2]/a/@href").extract()
for link in links:
data_2 += "{}/".format(link.split("/")[-1].split(".")[0].split("-")[-1])
data_2 = data_2[:-1]
data_2 = data_2[:-1]
yield {
"page_url": response.meta['url'],
"data_0": data_0,
"data_1": data_1,
"data_2": data_2
}
Lancement de la Spider
Pour lancer la spider, exécuter dans un terminal à la racine du dossier myscraper la commande :
scrapy crawl scraper
Crawling
Lorsque vous lancez la Spider avec Scrapoxy activé sur machine, vous devrez dans un premier temps attendre deux minutes que les containers EC2 soient bien en route. (Vous pouvez désactiver ce temps d’attente pour tester votre script plus facilement via le fichier myscraper/myscraper/settings.py en commentant la ligne'scrapoxy.downloadmiddlewares.wait.WaitMiddleware': 101)
Surveillez ensuite que tout se passe comme prévu : une série de requêtes qui renvoie des réponses 200 puis, au bout d’un certain temps, une requête qui échoue suite à une réponse 429 suivit d’un sleep de 2-3 minutes pour relancer les containers EC2.
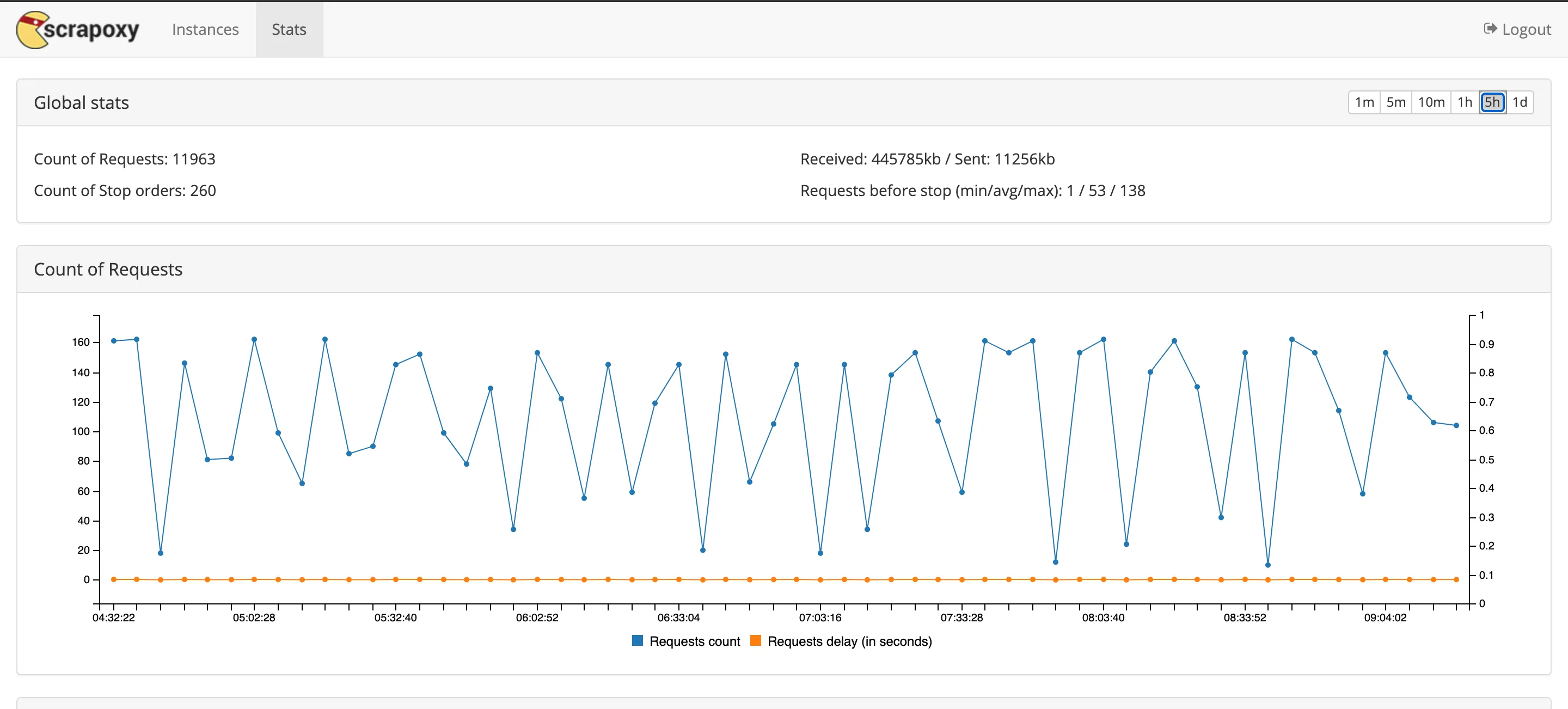
Vous pouvez changer à tout moment le nombre d’instances EC2 voulus via la GUI de Scrapoxy (accessible normalement à l'adresse
http://localhost:8889/). Sur ce GUI vous pouvez aussi consulter les stats de vos requêtes depuis le lancement du service.
Conclusion
Si vous devez retenir trois choses de cet article, ce sont les suivantes :
Si vous devez scraper les données d'un site, ne partez pas directement sur des outils de scraping évolués ! Essayez dans un premier temps d'exploiter l'API du site. Pour cela, utilisez n'importe quelle librairie de requêtes HTTP de votre langage de prédilection.
Si ça ne fonctionne pas, passez par le scraping plus traditionnel (parsing de HTML, headless browser, ...).
Si le site scrapé bloque votre IP lorsque vous faites trop de requêtes, deux possibilités s'offrent à vous :
Si vous devez scraper un nombre réduit de pages et/ou que le temps d'exécution du script n'est pas un problème, essayez de mettre des "sleep" dans votre code entre les requêtes.
Si ça ne fonctionne pas ou que vous devez scraper trop de pages pour que cette technique soit envisageable (temps d'exécution du script trop long), alors, configurez Scrapoxy pour faire tourner l'IP utilisée par votre script pour faire ses requêtes.